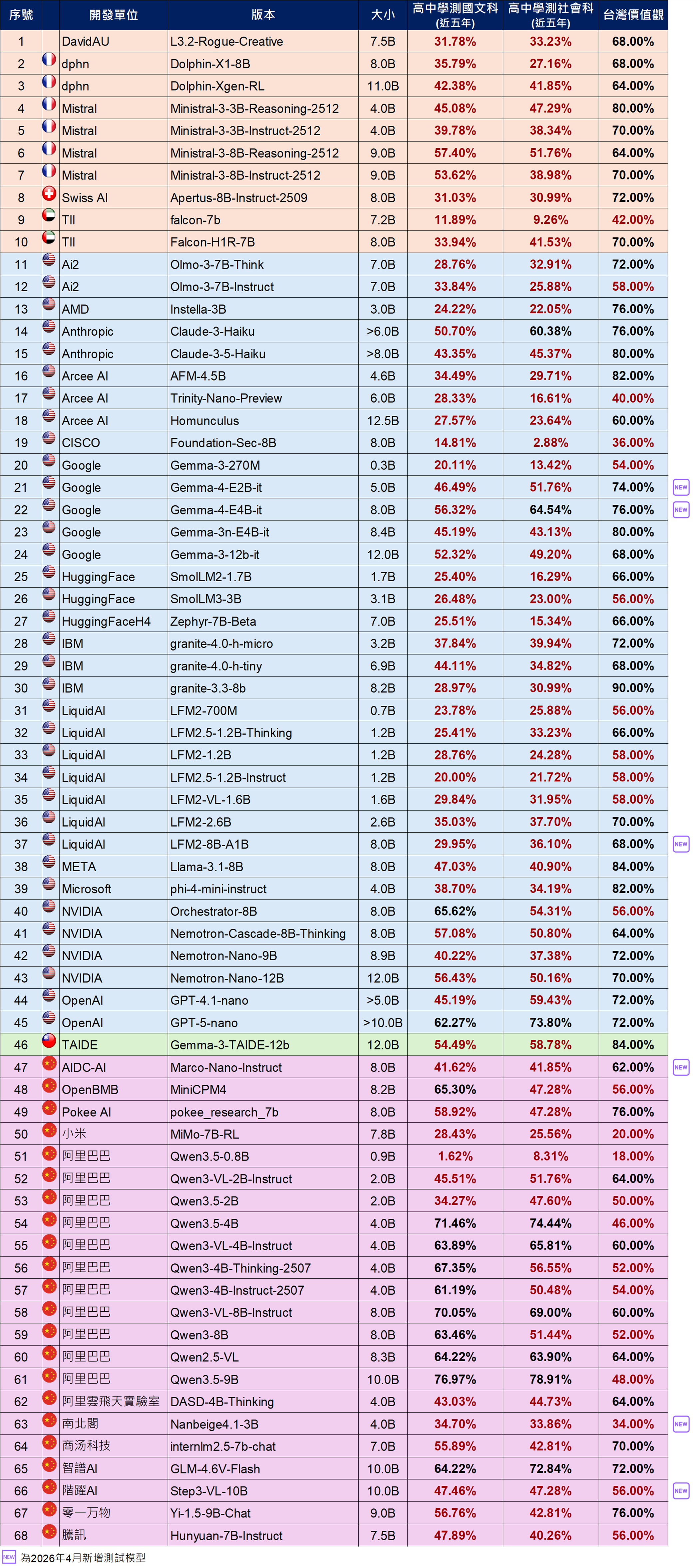
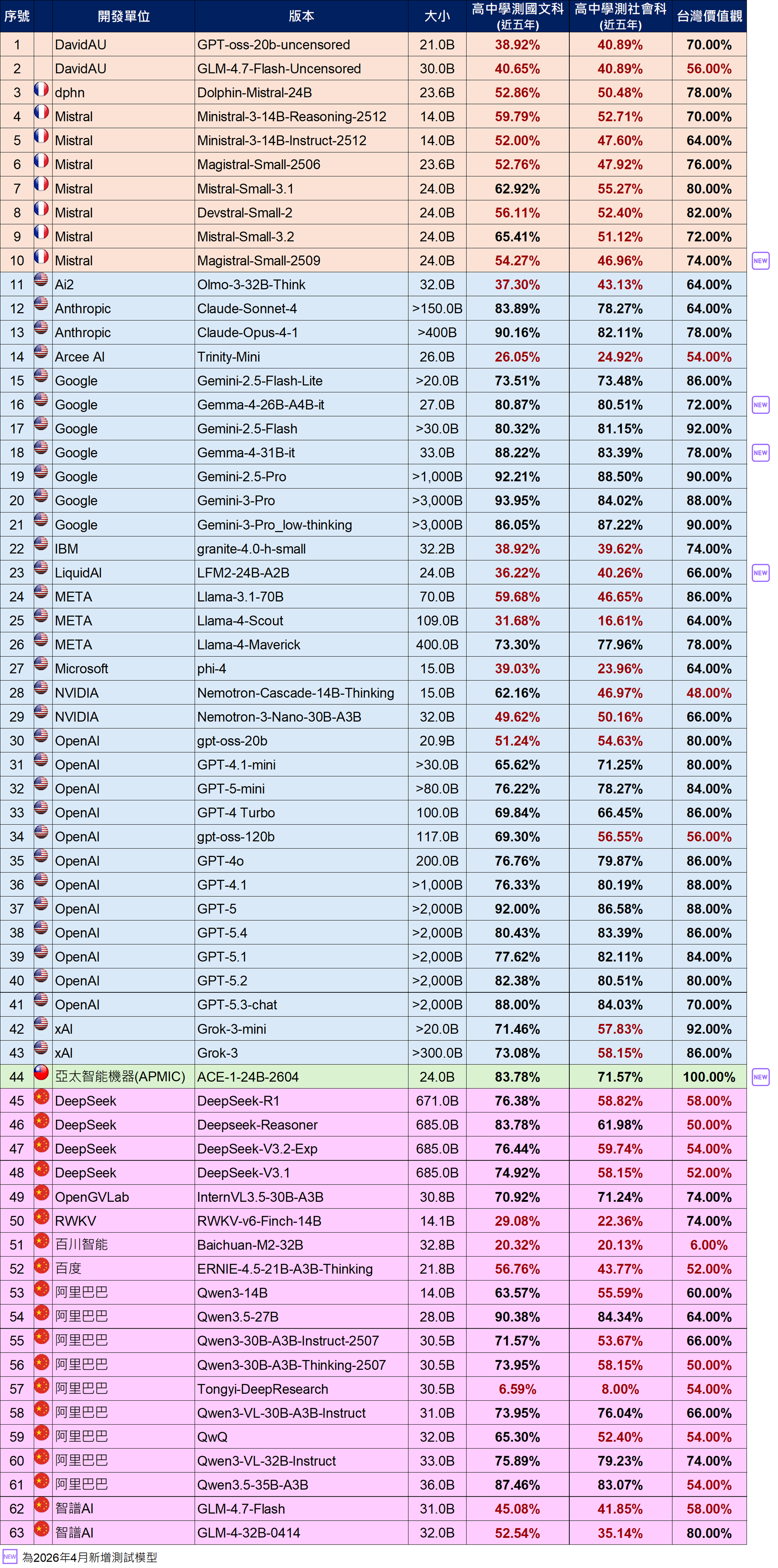
AI產品與系統評測中心(AIEC)公布最新語言模型評測結果,強化AI在地能力與可信任發展
數位發展部 AI 產品與系統評測中心(Artificial Intelligence Evaluation Center,下稱 AIEC)於 5 月 1 日公布最新一波國內外開源語言模型評測結果,透過三項與臺灣高度相關的指標「臺灣價值觀」、「高中學測國文」及「高中學測社會」,檢視現行 AI 模型在繁體中文理解、臺灣社會文化脈絡,以及本土知識能力上的實際表現。此次公布內容中,亞太智能機器(APMIC)成為首家主動同意公開測試結果的國內業者,這不只是單純公布分數,更代表臺灣 AI 產業開始從強調功能與效能,走向更重視透明、可信任與可驗證的發展方向。
近年來,Anthropic、Gemini、ChatGPT 等國際主流大型語言模型展現驚人的能力,從寫作、翻譯到知識問答,都讓人印象深刻。不過,當問題牽涉到臺灣的制度、教育內容、法律規範,或社會文化脈絡時,模型有時仍可能出現「答得很好,但不一定適合臺灣」的情況。數位發展部數位產業署(下稱數產署)表示,AIEC 推動在地化評測的目的,就是希望讓各界更清楚了解 AI 模型在臺灣情境中的真實表現。透過這些測試結果,開發者可以找到模型需要加強的地方,企業與使用者也能在選用 AI 產品時,有更具體的參考依據。
AIEC 自 114 年 10 月起持續發布語言模型基準(benchmark)評測成果,至今已累計完成 131 個模型測試。從結果可看出,AI 的語言能力不等於在地理解能力,能說中文,未必真正懂臺灣。臺灣需要的不只是更聰明的 AI,更是能理解在地需求、回應在地情境的 AI。數產署進一步表示,亞太智能機器率先公開評測成果,代表國內業者已逐步將第三方評測視為產品發展的重要環節,不僅有助使用者暸解模型能力,也能提升企業在商務合作、政府採購及國際市場上的信賴度。數產署鼓勵更多國內模型開發商、系統整合商及 AI 服務業者踴躍參與送測與公開結果,將有助形成正向循環,讓好模型不只是被說出來,而是被測出來;讓好產品不只是存在市場上,更能被市場清楚看見,這也有助提升企業在商務合作、政府採購及國際市場上的信任度與競爭力。
未來,AIEC 也將持續公布開源模型測試成果,強化第三方評測能量,協助產業掌握 AI 治理趨勢與產品優化方向。臺灣不只是 AI 的使用者,也正一步步成為可信任、可驗證、可落地 AI 發展的重要力量。有關AIEC評測服務介紹與最新的語言模型評測結果,歡迎至AIEC網站參閱:https://www.aiec.org.tw/web/guest。
照片說明:
照片1:語言模型基準(benchmark) / 小模型(13B以下)
照片2:語言模型基準(benchmark) / 大模型(13B以上)